Правила сопоставления
Данные во вкладке представлены в табличном виде (Рисунок 1). Вкладка “Правила сопоставления” предназначена для создания, редактирования и удаления правила сопоставления.
Правила сопоставления указывают на хранилище данных, в котором будет производиться поиск дубликатов, а также выбирают количество и состав алгоритмов сопоставления.
Создание правила
Чтобы создать правило сопоставления:
Убедитесь, что включен режим черновика и выбран черновик.
Нажмите кнопку
 Создать правило, расположенную в правой части экрана.
Создать правило, расположенную в правой части экрана.В результате действия откроется выдвижная панель с настройками правила и алгоритмов.
Заполните основные параметры правила (Рисунок 2):
Имя - системное имя правила. Имя должно начинаться с буквы и содержать только латинские буквы, цифры, символы "-", "_". Не может содержать пробелы. Недоступно для редактирования после сохранения.
Отображаемое имя - имя правила, которое будет отображаться пользователям.
Описание - любая дополнительная информация о правиле сопоставления.
Хранилище - содержит набор алгоритмов, который может быть расширен за счет пользовательских библиотек. На данный момент в системе реализовано хранилище на основе базы данных Postgres, содержащее алгоритмы сопоставления по точному и неточному соответствию и по набору значений.
В секции "Алгоритмы" выберите необходимый алгоритм сопоставления из списка доступных.
Для добавления нескольких алгоритмов нажмите кнопку
 Добавить, расположенную справа от заголовка "Алгоритмы", или Удалить, чтобы стереть лишний.
Добавить, расположенную справа от заголовка "Алгоритмы", или Удалить, чтобы стереть лишний.Нажмите "Сохранить" после заполнения всех параметров и опубликуйте черновик.
После завершения работы с правилами перейдите во вкладку Наборы правил.
Алгоритмы сопоставления
Точное соответствие - сравнивает записи по точному соответствию значений атрибута.
"Регистронезависимый поиск" - флаг, определяющий, будет ли при поиске сопоставлений учитываться регистр (для строковых типов атрибутов).
Неточное соответствие - сравнивает записи по неточному соответствию значений, используя стемминг и триграммы (только для строковых атрибутов).
"Не учитывать регистр" - отключает чувствительность к регистру.
"Использовать триграммы" - включает использование триграмм - трех строчных символов, набор которых перебирает все трехсимвольные варианты предложения. Например, предложение "Evangelist 21" будет разбито на следующие триграммы: " e", " ev", "eva", "van", "ang", "nge", "gel", "eli", "lis", "ist", "st ", " 2", " 21".
При включении параметра предложение дробится на триграммы, выкидывая лишние пробелы и добавляя 2 пробела в начале. Кластеры образуются при сравнении предложения и всех триграмм. После этого сравнения выдается score - на сколько предложение удовлетворяет всем триграммам от 0 до 100. Если score >= 65, то предложение добавляется в кластер. Это дает возможность добавлять в кластер слова с опечатками. Например, в кластер "Evangelist" попадут "Evangelistz", "Evangelist z", "zvangelist", "Eangelist ".
"Порог схожести" - отсекает наборы триграмм по коэффициенту схожести. Значение в диапазоне от 0.00 до 1.00 включительно. По умолчанию = 0.65.
"Использовать tsquery" - позволяет использовать tsquery, содержащий искомые лексемы, объединяемые логическими операторами & (И), | (ИЛИ) и ! (НЕ), а также оператором поиска фраз <-> (ПРЕДШЕСТВУЕТ).
При включении параметра предложение дробится на лексемы и соединяется разделителем '&'. Например, было: "Петя шел домой". Стало: 'Петя' & 'шел' & 'домой'. Далее к тексту каждой записи применяется оператор postgress '@@', что позволяет найти все записи, в которых есть все лексемы, которые были в исходном тексте. В кластер попадет и "Петя шел домой", и "шел домой Петя", и "шел Петя домой", и "Петя домой шел", и "домой Петя шел".
"Язык содержимого" - определяет язык ввода для tsquery. В текущей реализации поддерживаются только русский и английский (по умолчанию).
"Тип объединения" - тип объединения лексем в объектах tsquery (определяет тип группировки при сравнении в tsquery). В текущей реализации поддерживаются & (И) - объединяются все токены и | (ИЛИ) - объединяется хотя бы один токен. По умолчанию: & (И).
Сопоставление наборов значений - сравнивает записи по имеющимся у них связям по пересечению экземпляров или по их полному соответствию.
"Тип сопоставления" - позволяет выбрать механизм сопоставления: по пересечению (если хотя бы один экземпляр подобъекта совпадает) или полному соответствию (если совпадают все экземпляры подобъекта).
"Учитывать периоды подобъектов" - флаг, определяющий попадание записи в кластер, если совпал хотя бы 1 экземпляр связи, и период действия этой связи имеет пересечение. Подобъекты - это объекты, которые используются для сравнения, например, связи.
Доп. параметры алгоритмов точного/неточного соответствия:
Учитывать null - при включении разрешается сопоставление по значению null в выбранном столбце таблицы сопоставления. Записи без классификатора добавляются в БД с значением null. Исходя из null == null такие записи объединяются в кластер. Важно: Параметр сильно увеличивает нагрузку при вычислении, поэтому необходимо использовать его с осторожностью. Сочетание параметра с алгоритмом Неточного соответствия и большим количеством данных может приводить к зависанию за счет большой вычислительной нагрузки.
Учитывать пустые строки - при включении разрешается сопоставление по пустой строке в выбранном столбце таблицы сопоставления. Пустые строки - строки нулевой длины, а также состоящие только из пробелов.
Сопоставлять null с пустыми строками - при включении разрешается сопоставление по null и пустым строкам между собой. Включение доступно, только если включены обе опции "Учитывать null" и "Учитывать пустые строки".
Примечания:
Указанные параметры влияют только на сопоставление по строковым колонкам таблиц.
Для алгоритмов точного/неточного соответствия пробелы в начале и конце строк не влияют на сопоставление - т.е. используется значение строки, как если бы этих пробелов не было.
При включенных одновременно флагах "Использовать триграммы" и "Использовать tsquery", если хотя бы один из способов определил сущность в кластер, то сущность определяется в кластер.
Удаление правила
Чтобы удалить правило сопоставления:
Убедитесь, что включен режим черновика и выбран черновик.
В крайнем левом столбце отметьте галочкой строку с необходимым правилом (одну или несколько).
Нажмите кнопку Удалить правило, расположенную в правом верхнем углу вкладки.
Подтвердите или отмените действие.
Совет
Удаление назначенных правил сопоставления происходит в обратном порядке по вкладкам: Назначение правил → Наборы правил → Правила сопоставления → Таблицы сопоставления
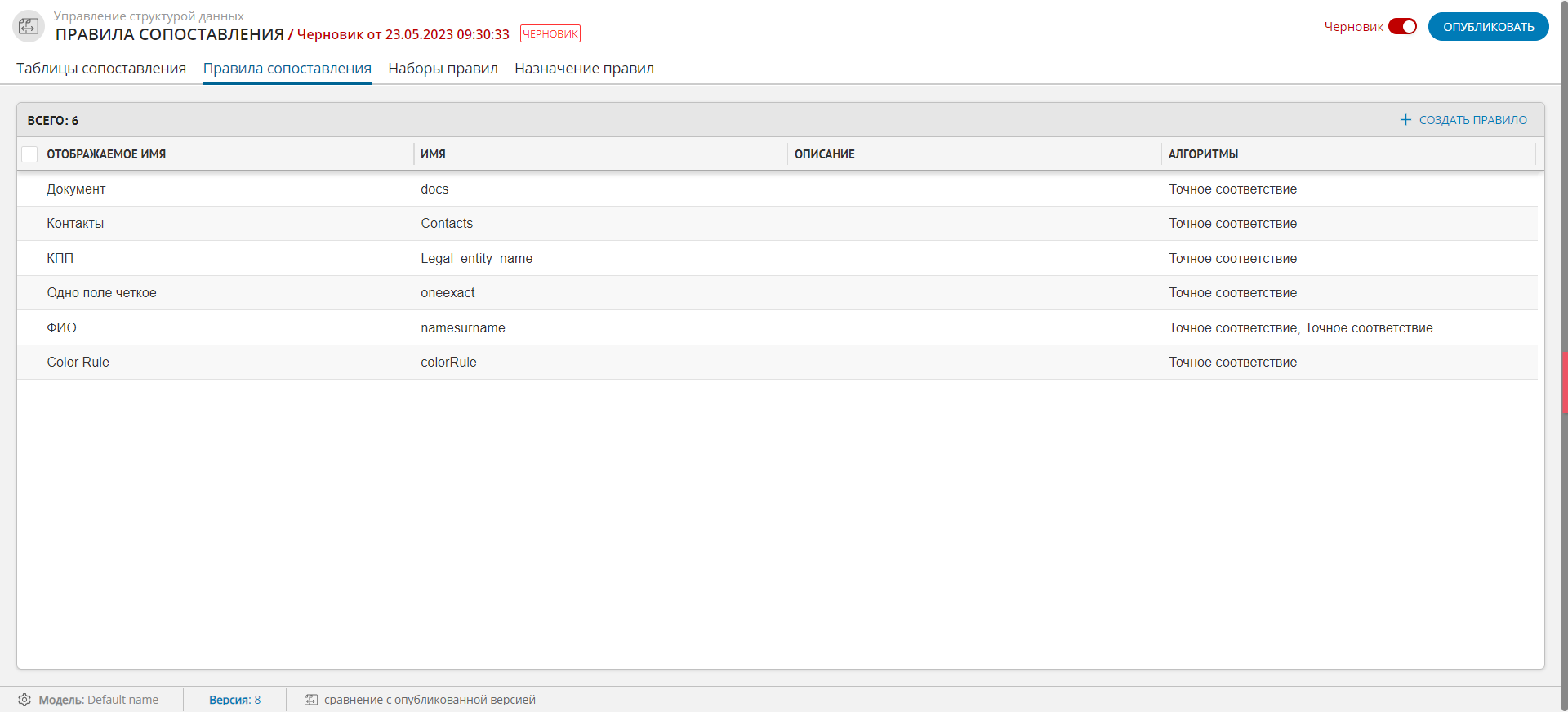
Рисунок 1 – Вкладка "Правила сопоставления"
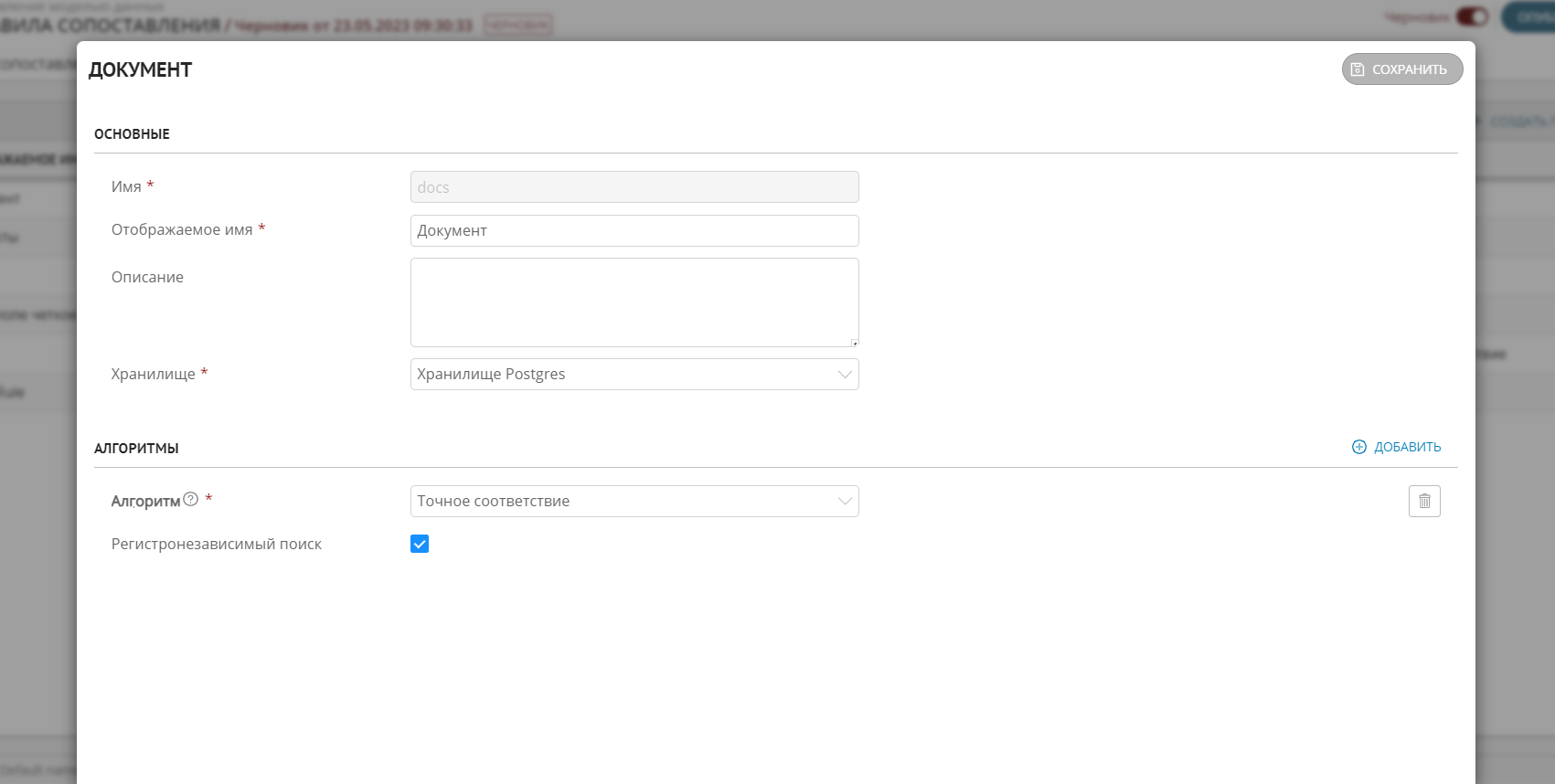
Рисунок 2 – Параметры правил сопоставления