Сравнение и объединение дубликатов
Просмотр состава кластера
Просмотр содержимого кластера осуществляется при нажатии на строку с именем кластера в разделе "Дубликаты".
В результате действия откроется выдвижная панель с подробной информацией о кластере: по какому правилу сопоставления или набору правил сформирован кластер, дате формирования и количестве записей в кластере (Рисунок 1). Ниже будет сформирована таблица с перечнем записей, вошедших в кластер дубликатов, состоящая из следующих столбцов:
Отображаемое имя - имя главного отображаемого атрибута записи.
ID записи - уникальный идентификационный номер записи.
Тип - тип пространства, в котором находится запись (реестр/справочник).
Название - название реестра/справочника, содержащего запись.
Если на реестр, в котором содержатся дубликаты, ранее был назначен классификатор, то в таблице записей также будет отображаться столбец "Классификация".
Примечания:
Переход в карточку записи доступен при нажатии на ID записи. Карточка откроется в новой вкладке браузера
В записях иерархического справочника также сравнивается родительский узел.
При сравнении связей по умолчанию отображается только главный отображаемый атрибут связанной записи. При нажатии на иконку стрелки рядом с именем связи и выборе связанной записи также отображаются атрибуты связи.
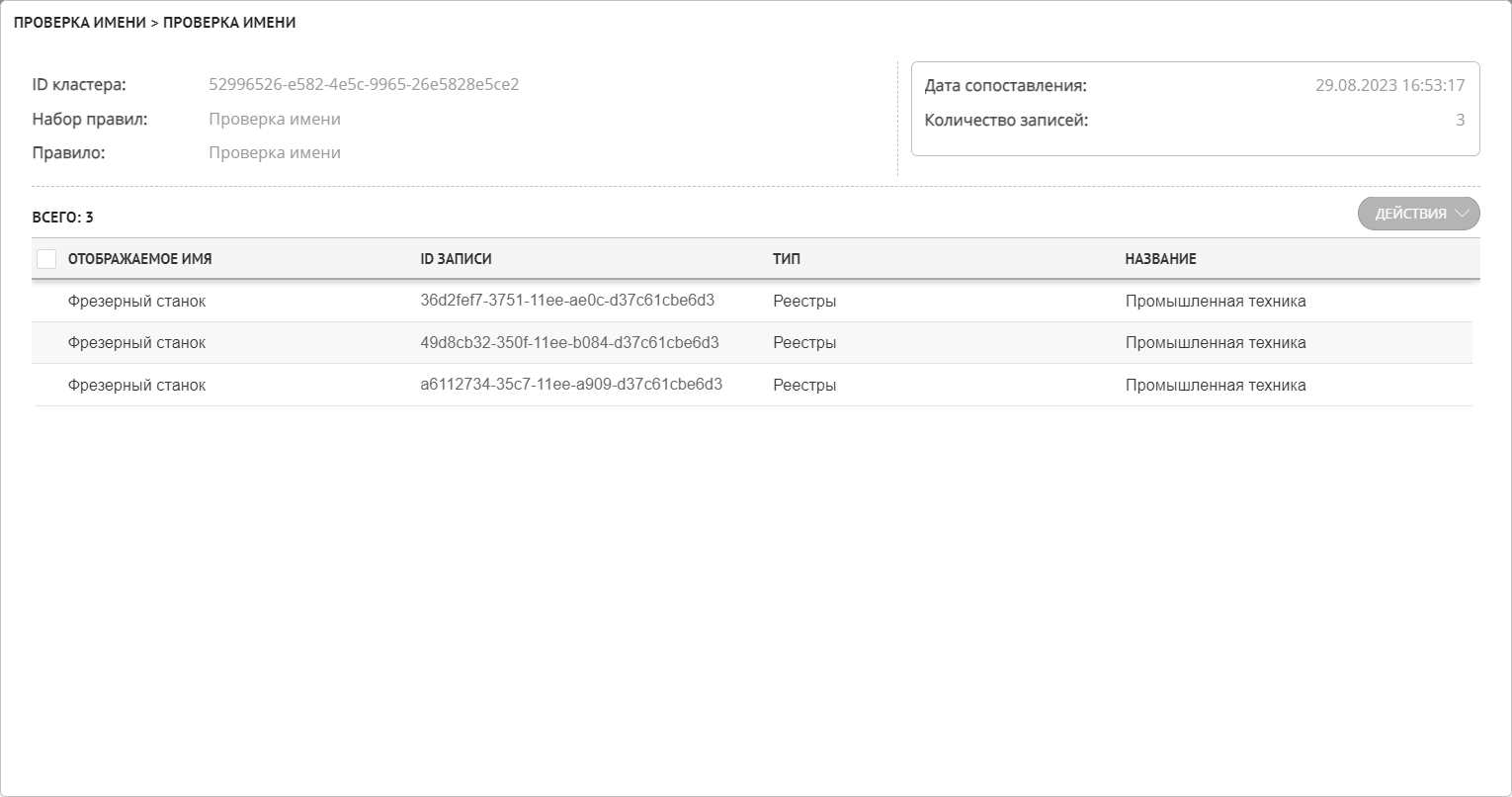
Рисунок 1 – Выдвижная панель с содержимым кластера дубликатов
Сравнение дубликатов
Чтобы сравнить записи кластера:
Откройте содержимое необходимого кластера.
Выделите галочками требуемые для сравнения записи. Записи должны находиться в рамках одного и того же пространства - конкретного реестра или справочника, в противном случае кнопка "Действия" будет неактивна.
Нажмите кнопку "Действия", которая становится активной после выбора двух и более записей, и выберите "Сравнить и объединить".
В результате действия откроется экран сравнения дублирующихся записей в табличном виде (Рисунок 2).
Бледно-голубым цветом выделяются различающиеся ячейки.
Для отображения только различающихся элементов нажмите кнопку
 "Только отличия".
"Только отличия".Чтобы изменить табличный вид представления на список нажмите кнопку
 "Сменить вид".
"Сменить вид".
Объединение дубликатов
Чтобы объединить записи кластера:
При необходимости исключите из сравнения неподходящие записи. Необходимо учитывать, что в дальнейшем все записи-дубликаты из сравнения будут объединены в единую запись-победитель.
На экране сравнения запись-победитель помечена значком
 . При необходимости назначьте победителем другую запись, нажав на значок
. При необходимости назначьте победителем другую запись, нажав на значок  "Определить победителем" слева от заголовка ID записи (Рисунок 2).
"Определить победителем" слева от заголовка ID записи (Рисунок 2).При необходимости выберите значения атрибутов (в т.ч. комплексных) из других исходных записей. Для этого нажмите кнопку
 "Выбрать", которая появляется при наведении на строку атрибута. В результате действия выбранный атрибут будет помечен значком
"Выбрать", которая появляется при наведении на строку атрибута. В результате действия выбранный атрибут будет помечен значком 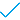 .
.Конечный результат объединения отображается в крайнем левом столбце и выделен серым цветом.
Нажмите кнопку "Объединить записи" в правом верхнем углу окна и подтвердите действие.
В результате действия записи будут объединены, а кластер удален.
Результат объединения будет доступен в разделе "Данные".
Предупреждение
В окне консолидации отключена возможность выбора записи и ее путей, если период ее актуальности не затрагивает текущий момент времени
Рисунок 2 – Экран сравнения записей кластера
Схема автоматического определения записи-победителя
Алгоритм консолидации кластера записей-дубликатов:
Etalon ID не является самой записью, а лишь привязкой, к которой относится запись. Его значение не влияет на атрибуты, поскольку консолидация данных выполняется на основе весов источников, приоритетов атрибутов или даты создания записи (выбирается самая актуальная).
Возможен выбор записи в качестве эталонной путем нажатия на ID. В этом случае в эталонную фиксируется не только сам идентификатор, но и все атрибуты записи.
Связи консолидируются по принципу обращения к лучшему значению записи: связи берутся целиком из записи-победителя.
Связи группируются по точке назначения (to).
При наличии нескольких связей с одинаковой точкой назначения, один из Etalon ID связи назначается победителем, а все связанные Origin ID переносятся на него.
Связи, которые проиграли в кластере записей и не имеют совпадений по точке назначения, переписываются на победителя.
При объединении записей иерархического справочника: родительским узлом объединенной записи становится родительский узел записи-победителя.
Примечания
Настройка ID не подлежит изменению — он всегда назначается автоматически.
При сравнении связей по умолчанию отображается только главный отображаемый атрибут связанной записи. При нажатии на иконку стрелки рядом с именем связи и выборе связанной записи также отображаются атрибуты связи.
Если один из сравниваемых атрибутов пустой, но все же выбран как победитель, то в итоговой записи все равно атрибут будет заполнен (для ситуаций, когда запись-победитель уже имела значение атрибута). Пустой атрибут не может перекрыть существующий атрибут при объединении.
В таблице объединения дубликатов невозможно выбрать отдельные связи в качестве победителей, так как связи в объединенной записи будут взяты из записи-победителя.
Чтобы удаленные записи не отображались в кластере, необходимо запустить операцию сопоставления данных (matchingJob).